Introduction
Hello, today we’ll be looking at how we can reverse engineer a lazy importer with a real life example. I’ll be using Roblox’s Hyperion as a base to reverse engineer as their implementation is a little bit different to how they’re normally implemented.
Background information
To begin, we’ll need to know what a lazy importer really is and what its use case is. A lazy importer will essentially create small stubs of code that will find a specific function that you’re looking to call and allow you to invoke it while also masking it from the import descriptor. When you have access to the import table of a binary file, it makes life easier to reverse engineer that file because we’d be able to directly see all xrefs (cross references) and understand exactly what’s going on in a good handful of places - this is very helpful when working against some form of anti-cheat/anti-tamper because these always rely on windows api specific functions. Here’s an example of a populated imports descriptor and how it would look like when reverse engineering.
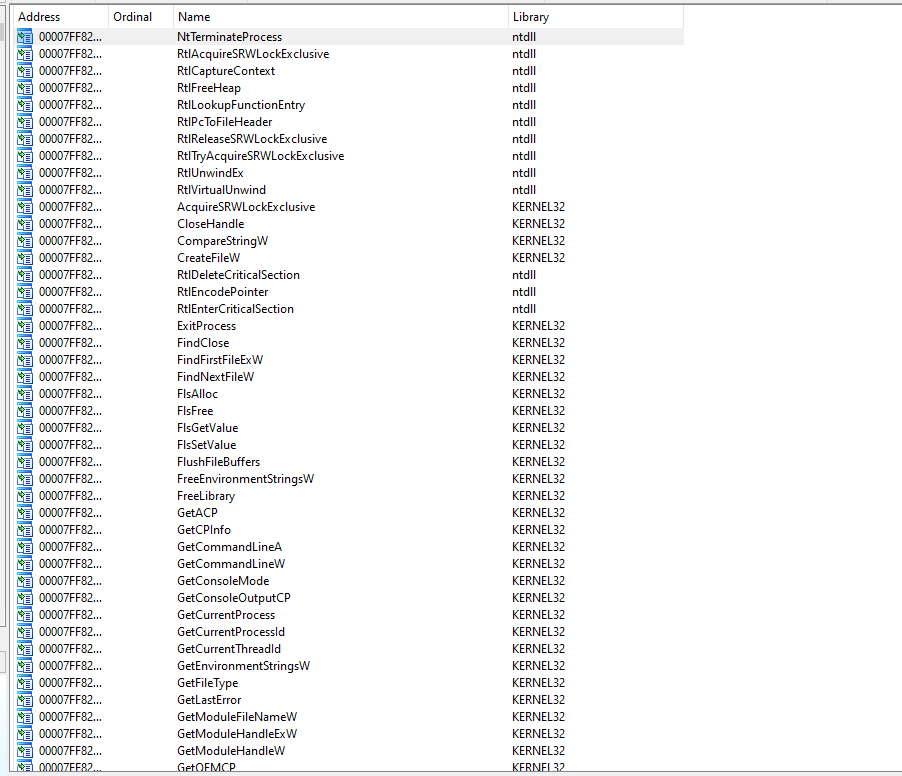 If we were to check any xref’s to any of these, it would help us understand the pseudocode easier, for example.
If we were to check any xref’s to any of these, it would help us understand the pseudocode easier, for example.
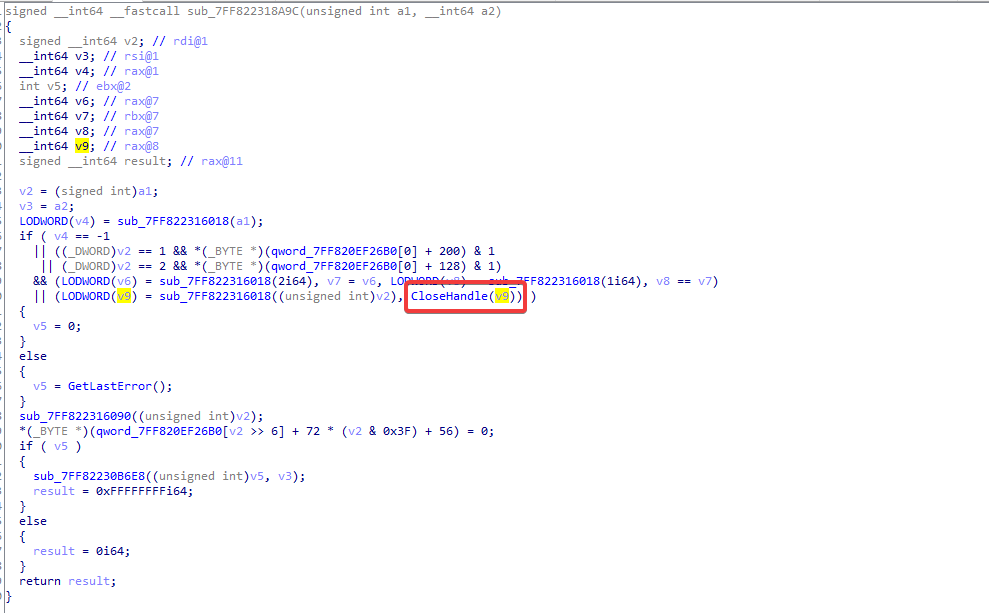 We can easily infer that v9 is a handle and that the function before it must return some form of handle. This is just a really minimal example.
We can easily infer that v9 is a handle and that the function before it must return some form of handle. This is just a really minimal example.
Lazy Importer
I’m not going to go into absolute detail but essentially, the way a lazy importer works is it creates stubs that iterates through the PEB of the local process and finds the specific module, the specific module name will also be hashed with two keys. There’s something which I would call an init key and a multiplier. The encryption used is a form of a rolling XOR. Let’s talk about how this algorithm works.
Rolling XOR
A rolling XOR will have two keys, the init key (as i mentioned previously) and the multiplier, the init key is pretty simple, it’s used as the starting value within the algorithm. Here’s the simple transformation.
mov rcx, character
mov rax, last_key
xor rax, rcx
imul rax, multip_key
or…
(character ^ last_key) * multip_key
You might be wondering why there’s a “last_key” and not the init key being used here, it’s called a rolling xor - the result is actually built up off of the previous entry each time.
Traversing the PEB
Now that we’ve talked about the algorithm used for the hashes, we’ll talk about how it typically will start out when it comes to invoking a lazily imported function. It all begins with three simple instructions
mov rax, gs:60h
mov rax, [rax+18h]
add rax, 0x10
or …
std::uint64_t peb = __readgsqword(0x60);
std::uint64_t ldr = *reinterpret_cast<std::uint64_t*>(peb + 0x18);
std::uint64_t InLoadOrderModuleList_addr = ldr + 0x10;
What this is doing is, the first mov will get the PEB. Every process has its own PEB and you can just look at it as some form of descriptor. The second instruction will get the LDR entry from the PEB. The LDR entry essentially contains every loaded module within the process, this is how they’re iterating over each one. After these instructions, there’s some more instructions related to the actual lazy importer but I’ll cover these later on in the section covering a live example, for now we’ll move onto these next instructions;
mov r9, rax
mov r9, [r9]
or…
std::uint64_t entry = *reinterpret_cast<std::uint64_t*>(InLoadOrderModuleList_addr);
We directly dereference the address to get a doubly linked list of loaded modules, we’re going to cast these to _LDR_DATA_TABLE_ENTRY.
movzx r10d, word ptr [r9+58h]
or…
std::uint16_t unicode_name_length = *reinterpret_cast<std::uint16_t*>(entry + 0x58);
Preparing the DLL
The entry + 0x58 address will lead to the start of a unicode string for the BaseDllName, by dereferencing it, we actually get the length of the name.
shr r10d, 1
mov r11, [r9+60h]
or…
// Get the character length of the unicode string
// shift right by 1 is the same as dividing by two
unicode_name_length /= 2
std::uint64_t name_bytes = *reinterpret_cast<std::uint64_t*>(entry + 0x60);
What’s happening here is, we’re getting the actual length of the character’s in the string. Unicode strings length are essentially nm_of_characters * 2 since the Length field stores the amt of bytes. The name bytes is exactly as it says, it gets the pointer to the actual bytes of the dll name. Here’s where it starts to get more interesting though.
mov ebx, r10d
and ebx, 0FFFFFFFEh
or…
std::uint32_t pair_len = unicode_name_length - (unicode_name_length % 2);
What this is actually doing is, it splits the string into pairs of two. There’s some assembly before this which actually handles if it’s a odd sized string, it essentially still handles all the pairs but has an extra last case for the last character that was left out.
The hasher
Now, onto the final part of the hashing - the algorithm…
; First byte
movzx r14d, word ptr [r11+rdi*2]
lea r15d, [r14-41h]
mov r12d, r14d
or r12d, 20h
cmp r15w, 1Ah
cmovnb r12d, r14d
movzx r14d, r12b
xor r14, rsi
imul r14, r8
; Second byte
movzx esi, word ptr [r11+rdi*2+2]
lea r15d, [rsi-41h]
mov r12d, esi
or r12d, 20h
cmp r15w, 1Ah
cmovnb r12d, esi
movzx esi, r12b
xor rsi, r14
imul rsi, r8
add rdi, 2
or…
std::uint64_t lazy_deporter::apply_character(std::uint8_t current_char,
const std::uint64_t key,
const std::uint64_t multip_magic,
const bool requires_upper) const {
// Ensure lowercase character, do not encrypt as uppercase if it's a module
// name
if (std::isupper(current_char) && requires_upper)
current_char = std::tolower(current_char);
/*
mov reg1, key
xor reg1, reg2
imul reg1, multip_magic
*/
return (current_char ^ key) * multip_magic;
}
std::expected<std::uint64_t, std::string>
lazy_deporter::get_hash(const char *entry, lazy_keys keys, bool is_mod) const {
// Create local copy of current output, at start this is defaulted to the init
// magic
std::uint64_t encrypted_return = keys.lazy_init_key;
// Hyperion splits the input string into streams of two characters, so we'll
// do the same here. We need to ensure that we get the last tuple index.
const std::size_t len = strlen(entry),
tuple_len = strlen(entry) - (strlen(entry) & 1);
// Iterate through each pair
std::size_t idx = 0;
while (idx != tuple_len) {
// Encrypt first character
encrypted_return = this->apply_character(entry[idx], encrypted_return,
keys.lazy_multip, is_mod);
// Encrypt second character
encrypted_return = this->apply_character(entry[idx + 1], encrypted_return,
keys.lazy_multip, is_mod);
// Move onto next tuple
idx += 2;
}
// Check if odd sized string, if so we need to handle the last char that was
// left out
if (len & 1) {
encrypted_return = this->apply_character(entry[len - 1], encrypted_return,
keys.lazy_multip, is_mod);
}
// Return encrypted magic to user
return encrypted_return;
}
That’s pretty much it, it essentially applies the rolling xor algorithm to each character in every pair, if it’s a module name it’ll enforce a lowercase input only which you can see happening in the assembly. The function hashing is exactly the same except it doesn’t enforce lowercase.
Functions
As said before, functions are basically identical except they’re retrieved from the export table of the module. I’ll save you the boring details but, after it matches the hash it will get the export directory of the dll. Once it does this, it’ll iterate through all the exported functions of the module, once it matches the function hash to an export, and directly invoke the function from the base + rva to the function found through the export table. This happens differently within Hyperion, hyperion will actually obfuscate the function address and deobfuscate it immediately after and invoke it. The obfuscation is built up off of some trivial byte transformation on EVERY byte within the address - it uses some sort of rng value in the transformation.
mov rax, [rbp+940h+var_C0]
inc al
and al, 3
movzx esi, al
movzx r15d, byte ptr [rbp+940h+var_138]
xor r15b, r8b
not r15b
rol r15b, 1
mov r12d, r8d
shr r12d, 8
xor r12b, byte ptr [rbp+940h+var_140]
not r12b
rol r12b, 1
lea r9, unk_7FF820F0E4B4
mov [r9+rsi*8+1Ch], r15b
mov [r9+rsi*8+1Dh], r12b
mov r13d, r8d
shr r13d, 10h
xor r13b, byte ptr [rbp+940h+var_198]
not r13b
rol r13b, 1
mov [r9+rsi*8+1Eh], r13b
mov eax, r8d
shr eax, 18h
xor al, byte ptr [rbp+940h+var_1B0]
not al
rol al, 1
mov [r9+rsi*8+1Fh], al
mov r14, r8
shr r14, 20h
movzx ebx, byte ptr [rbp+940h+var_6E8]
xor r14b, bl
not r14b
rol r14b, 1
mov rcx, r8
shr rcx, 28h
movzx r11d, byte ptr [rbp+940h+var_B8]
xor cl, r11b
not cl
rol cl, 1
mov [r9+rsi*8+20h], r14b
mov [r9+rsi*8+21h], cl
mov rdx, r8
shr rdx, 30h
movzx edi, byte ptr [rbp+940h+var_80]
xor dl, dil
not dl
rol dl, 1
mov [r9+rsi*8+22h], dl
shr r8, 38h
movzx r10d, byte ptr [rbp+940h+var_88]
xor r8b, r10b
not r8b
rol r8b, 1
mov [r9+rsi*8+23h], r8b
mov cs:byte_7FF820F0E4C0, sil
not r15b
ror r15b, 1
xor r15b, byte ptr [rbp+940h+var_138]
not r12b
ror r12b, 1
xor r12b, byte ptr [rbp+940h+var_140]
not r13b
ror r13b, 1
xor r13b, byte ptr [rbp+940h+var_198]
not al
ror al, 1
xor al, byte ptr [rbp+940h+var_1B0]
not r14b
ror r14b, 1
xor r14b, bl
not cl
ror cl, 1
xor cl, r11b
not dl
ror dl, 1
xor dl, dil
not r8b
ror r8b, 1
xor r8b, r10b
or…
std::uint64_t obfuscate_address(std::uint64_t func_addr,
std::uint8_t *xor_bytes,
std::uint8_t *rng_table) {
std::uint8_t current_index = (rng_table[0xC] + 1) & 3;
std::uint8_t obfuscated_bytes[8];
for (int idx = 0; idx < 8; idx++) {
std::uint8_t byte = (reinterpret_cast<std::uint8_t *>(&func_addr))[idx];
byte ^= xor_bytes[idx];
byte = ~byte;
byte = (byte << 1) | (byte >> 7);
obfuscated_bytes[idx] = byte;
rng_table[current_index * 8 + 0x1c + idx] = byte;
}
rng_table[0xC] = current_index;
std::uint64_t deobfuscated = 0;
for (int idx = 0; idx < 8; idx++) {
std::uint8_t byte = obfuscated_bytes[idx];
byte = ~byte;
byte = (byte >> 1) | (byte << 7);
byte ^= xor_bytes[idx];
(reinterpret_cast<std::uint8_t *>(&deobfuscated))[idx] = byte;
}
return deobfuscated;
}
This is, of course, directly invoked immediately after.
Hyperion Lazy Import overview
Everything we’ve currently discussed so far applies to hyperion, the only major difference is that they actually setup multiple different key sets, typically only one key set is used within a lazy importer but they’ve gone out of there way to add multiple - each set is different and are used to, most likely, mask all functions so that even if you find one, it won’t match the other.
Conclusion
I hope this helped you understand how a Lazy Importer is used and how we can reverse engineer it - Hyperion’s implementation is a really good public use case of this because it utilises multiple different keys as we talked about, they also obfuscate any return too. You can find a public repo dumping all of the lazily imported functions (If any are missing, it’s most likely that the pattern isn’t capturing all references but the core logic should be fine).